

SMART-LAB
Новый дизайн
Мы делаем деньги на бирже














Информация


Блог им. vlad1024
Исследование индекса оптимизма Smart Lab. Часть 2
- 25 сентября 2011, 20:34
- |

В предыдущей серии, мы пересчитали значении индекса, а так же нашли его корреляцию с приращениями индекса RTS, таким образом построив простейшую модель (Корреляция: 38.8%, СКО ошибки: 0.235), на этот раз мы попробуем значительно ее улучшить.
Для каждого из используемых факторов: Индекс РТС, индекс ММВБ, акции Сбербанк, акции Газпром, индекс Bovespa, индекс S&P, фьючер на нефть марки BRENT, фьючерс на золото и фьючерс на пару рубль/доллар, посчитаем: приращения логарифма (logdelta = log(Close) — log(Open)). По которым построим линейную регрессию этих приращений и значений индекса оптимизма. То есть формулу вида: индекс оптимизма = A0 + A1*РТС logdelta + A2*ММВБ logdelta + A3*S&P logdelta +…. В результате получим, что два статистически значимых фактора, приращения индекса РТС и индекса ММВБ, и здесь нас ждет первая неожиданность: значимыми оказываются не сами приращения, а их разница (то есть, приращение индекса РТС — приращение индекса ММВБ).
Таким образом выделим новый фактор: РТС logdelta — ММВБ logdelta, и попробуем построить на его основе модель (аналогичную той что была в первой части). Получим:
индекс оптимизма = 15.77*(РТС logdelta — ММВБ logdelta) + 0.095
(черным значения индекса, красным предсказания модели)

Как видно модель, чаще стала угадывать направление, и даже амплитуду, что выразилось в росте Корреляции: 38.8% -> 60%, и снижении СКО ошибки: 0.235 -> 0.202. Из чего можно сделать вывод, что разница приращений РТС и ММВБ является, основным наиболее существенным фактором влияющим на значения индекса оптимизма.
Попробуем еще немного усложнить модель, чтобы повысить ее предсказательную силу. Для каждого инструмента добавим следующие факторы: logdelta_l1 (приращение за предыдущий день) и logrange (log(high) — log(low)). Использую так же как и в предыдущих случаях линейную регрессию, мы выявим два фактора статистически значимо влияющие на значения индекса, это: sandp_logdelta_l1 (приращения S&P500 за предыдущий день) и brent_logrange (диапазон движения нефти за текущий день в лог масштабе log(high) — log(low)).
Используя уже выявленный фактор (разница приращений ММВБ и РТС) и эти два, построим новую, трех факторную модель. Получим:
индекс оптимизма = 16.22*rtsi_micex_logdelta + 4.93*sandp_logdelta_l1 + 6.91*brn_logrange — 0.1
или то же самое, но в масштабе приращений (а не их логарифмов):
индекс оптимизма = 0.0087*rtsi_micex_delta + 0.0043*sandp_delta_l1 + 0.0613*brn_range — 0.1
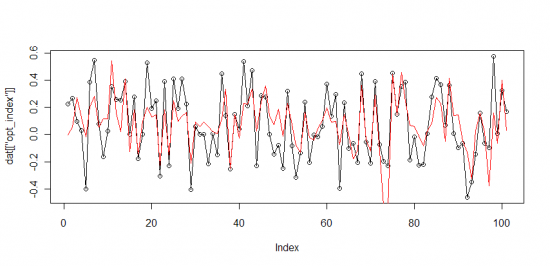
Корреляция: 60% -> 74%, СКО ошибки: 0.202 -> 0.170
Добавление большего количества факторов, с одной стороны несомненно могло еще больше улучшить формальные метрики, с другой стороны на такой небольшой выборке(100 значений) привело бы к переподгонке/переоптимизации и худшей предсказательной силе модели. Поэтому остановимся на выделенных трех статистически значимых факторах и попробуем улучшить структуру нашей линейной модели. Каким образом? Попробуем добавить нелинейность! То есть перейдем от линейной регрессии вида a0 + a1*factor1 + a2*factor2 +.., к обобщенным аддиативным моделям(gam/generalized additive model) вида F0 + a1*F1(factor1) + a2*F2(factor2) + ..., где F0, F1, F2 — какие-то нелинейные функции(не параметрические, чаще всего сплайны).
Для каждого из трех факторов получим функции вида:
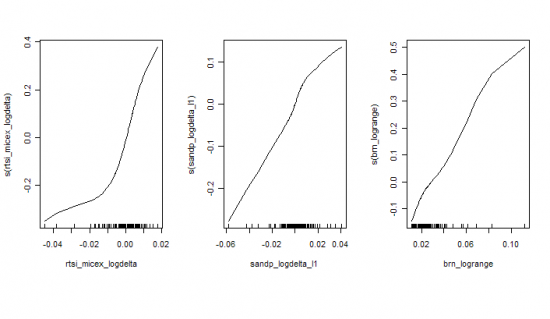
Как видно существенно нелинейно преобразование лишь для первого фактора(rts_micex_logdelta, разница приращений РТС и ММВБ). Поэтому остановимся на финальной модели вида: a0 + a1*F1(rts_micex_logdelta) + a2*sandp_logdelta_l1 + a3*brn_logrange. В результате получим:
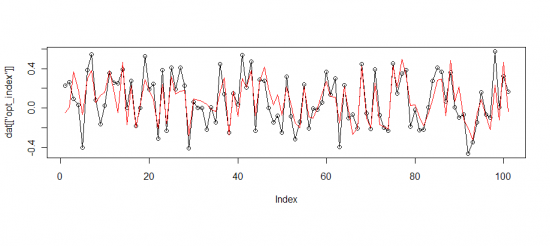
Как видно, значения предсказанные моделью, почти не отличаются от «настоящего» индекса. Корреляция: 74% -> 81%, СКО ошибки: 0.170 -> 0.146.
Ну и на последнем этапе, произведем форвардное тестирование модели, на новых данных полученных за неделю (19-23).
(черным значения индекса, зеленым трех факторная линейная модель, красным нелинейная обобщенная модель)
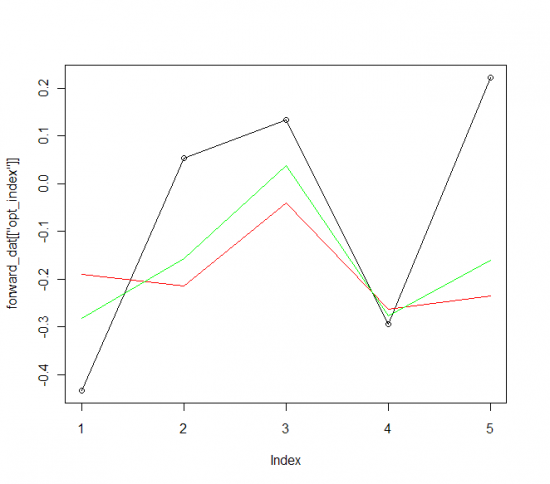
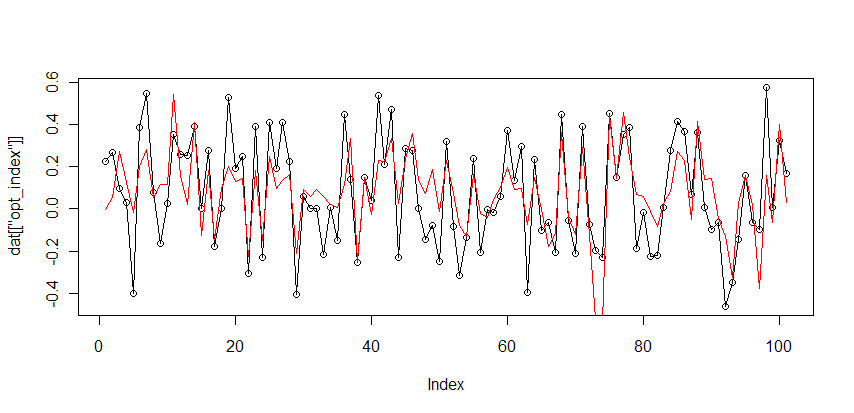
В общем видно, что линейная модель предсказывала немного лучше нелинейной, и обе они были хуже чем на истории, что скорее всего связанно с аномальным падением рынка.
Какие можно сделать выводы из проведенного исследования?
1. Индекс оптимизма скоррелирован с приращением S&P за предыдущий день, тоесть сентимент существенно запаздывает, «толпа» верит что движение S&P за прошлый день продолжится. (в отличии от рынка приращения, которого за текущий день не скоррелировано с приращением S&P за прошлый)
2. Индекс оптимизма скоррелирован с волатильностью нефти BRENT, то есть рост волатильности нефти воспринимается позитивно, а падение негативно.
3. Хотя индекс оптимизма скоррелирован с приращениями индекса РТС, наиболее значимым фактором является разница приращений РТС и ММВБ, что достаточно неожиданно, и у меня нет однозначной интерпретации на этот счет (можете предложить свою в комментариях)
И на последок, предикативность индекса оптимизма (по y приращение RTSI на следующий день, по x значения индекса):
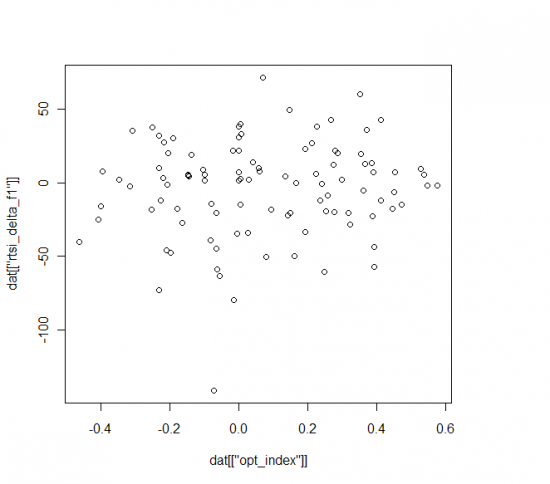
корреляция — 9%, что меньше статистической значимости, и меньше серийности RTSI — 20%(корреляция приращений текущего и следующего дня за период).
данные, картинки, код на R
Для каждого из используемых факторов: Индекс РТС, индекс ММВБ, акции Сбербанк, акции Газпром, индекс Bovespa, индекс S&P, фьючер на нефть марки BRENT, фьючерс на золото и фьючерс на пару рубль/доллар, посчитаем: приращения логарифма (logdelta = log(Close) — log(Open)). По которым построим линейную регрессию этих приращений и значений индекса оптимизма. То есть формулу вида: индекс оптимизма = A0 + A1*РТС logdelta + A2*ММВБ logdelta + A3*S&P logdelta +…. В результате получим, что два статистически значимых фактора, приращения индекса РТС и индекса ММВБ, и здесь нас ждет первая неожиданность: значимыми оказываются не сами приращения, а их разница (то есть, приращение индекса РТС — приращение индекса ММВБ).
Таким образом выделим новый фактор: РТС logdelta — ММВБ logdelta, и попробуем построить на его основе модель (аналогичную той что была в первой части). Получим:
индекс оптимизма = 15.77*(РТС logdelta — ММВБ logdelta) + 0.095
(черным значения индекса, красным предсказания модели)
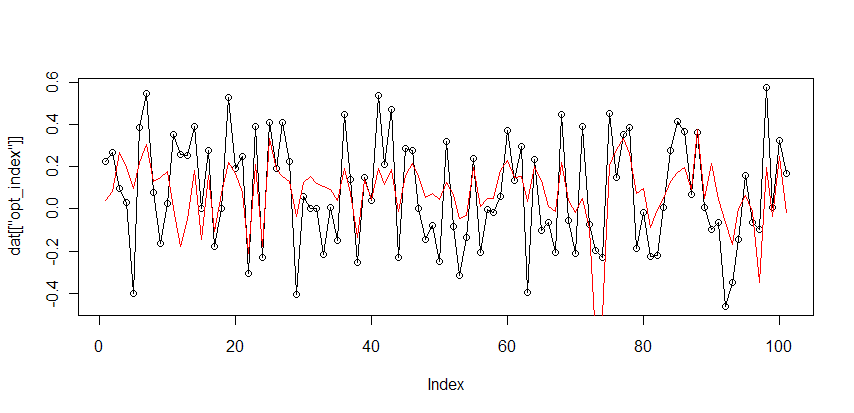
Как видно модель, чаще стала угадывать направление, и даже амплитуду, что выразилось в росте Корреляции: 38.8% -> 60%, и снижении СКО ошибки: 0.235 -> 0.202. Из чего можно сделать вывод, что разница приращений РТС и ММВБ является, основным наиболее существенным фактором влияющим на значения индекса оптимизма.
Попробуем еще немного усложнить модель, чтобы повысить ее предсказательную силу. Для каждого инструмента добавим следующие факторы: logdelta_l1 (приращение за предыдущий день) и logrange (log(high) — log(low)). Использую так же как и в предыдущих случаях линейную регрессию, мы выявим два фактора статистически значимо влияющие на значения индекса, это: sandp_logdelta_l1 (приращения S&P500 за предыдущий день) и brent_logrange (диапазон движения нефти за текущий день в лог масштабе log(high) — log(low)).
Используя уже выявленный фактор (разница приращений ММВБ и РТС) и эти два, построим новую, трех факторную модель. Получим:
индекс оптимизма = 16.22*rtsi_micex_logdelta + 4.93*sandp_logdelta_l1 + 6.91*brn_logrange — 0.1
или то же самое, но в масштабе приращений (а не их логарифмов):
индекс оптимизма = 0.0087*rtsi_micex_delta + 0.0043*sandp_delta_l1 + 0.0613*brn_range — 0.1
Корреляция: 60% -> 74%, СКО ошибки: 0.202 -> 0.170
Добавление большего количества факторов, с одной стороны несомненно могло еще больше улучшить формальные метрики, с другой стороны на такой небольшой выборке(100 значений) привело бы к переподгонке/переоптимизации и худшей предсказательной силе модели. Поэтому остановимся на выделенных трех статистически значимых факторах и попробуем улучшить структуру нашей линейной модели. Каким образом? Попробуем добавить нелинейность! То есть перейдем от линейной регрессии вида a0 + a1*factor1 + a2*factor2 +.., к обобщенным аддиативным моделям(gam/generalized additive model) вида F0 + a1*F1(factor1) + a2*F2(factor2) + ..., где F0, F1, F2 — какие-то нелинейные функции(не параметрические, чаще всего сплайны).
Для каждого из трех факторов получим функции вида:
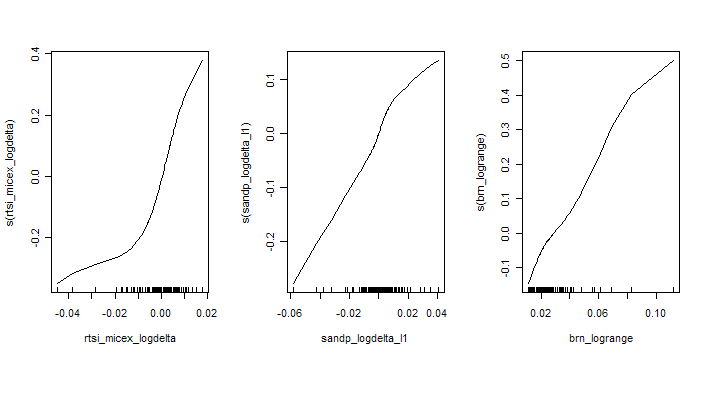
Как видно существенно нелинейно преобразование лишь для первого фактора(rts_micex_logdelta, разница приращений РТС и ММВБ). Поэтому остановимся на финальной модели вида: a0 + a1*F1(rts_micex_logdelta) + a2*sandp_logdelta_l1 + a3*brn_logrange. В результате получим:
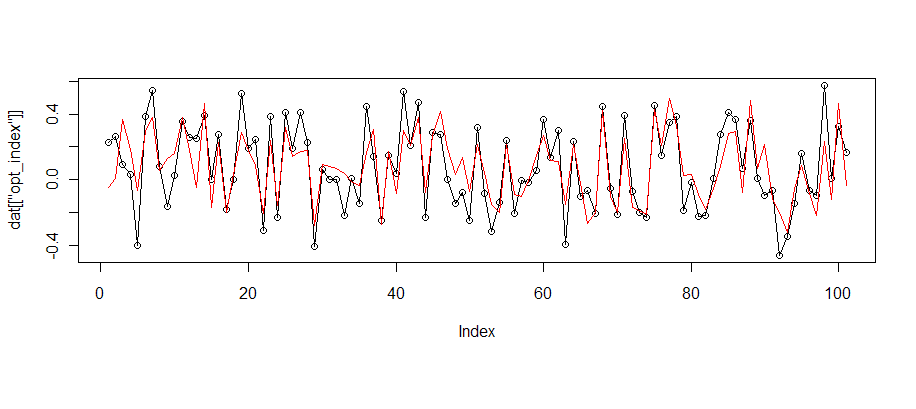
Как видно, значения предсказанные моделью, почти не отличаются от «настоящего» индекса. Корреляция: 74% -> 81%, СКО ошибки: 0.170 -> 0.146.
Ну и на последнем этапе, произведем форвардное тестирование модели, на новых данных полученных за неделю (19-23).
(черным значения индекса, зеленым трех факторная линейная модель, красным нелинейная обобщенная модель)

В общем видно, что линейная модель предсказывала немного лучше нелинейной, и обе они были хуже чем на истории, что скорее всего связанно с аномальным падением рынка.
Какие можно сделать выводы из проведенного исследования?
1. Индекс оптимизма скоррелирован с приращением S&P за предыдущий день, тоесть сентимент существенно запаздывает, «толпа» верит что движение S&P за прошлый день продолжится. (в отличии от рынка приращения, которого за текущий день не скоррелировано с приращением S&P за прошлый)
2. Индекс оптимизма скоррелирован с волатильностью нефти BRENT, то есть рост волатильности нефти воспринимается позитивно, а падение негативно.
3. Хотя индекс оптимизма скоррелирован с приращениями индекса РТС, наиболее значимым фактором является разница приращений РТС и ММВБ, что достаточно неожиданно, и у меня нет однозначной интерпретации на этот счет (можете предложить свою в комментариях)
И на последок, предикативность индекса оптимизма (по y приращение RTSI на следующий день, по x значения индекса):
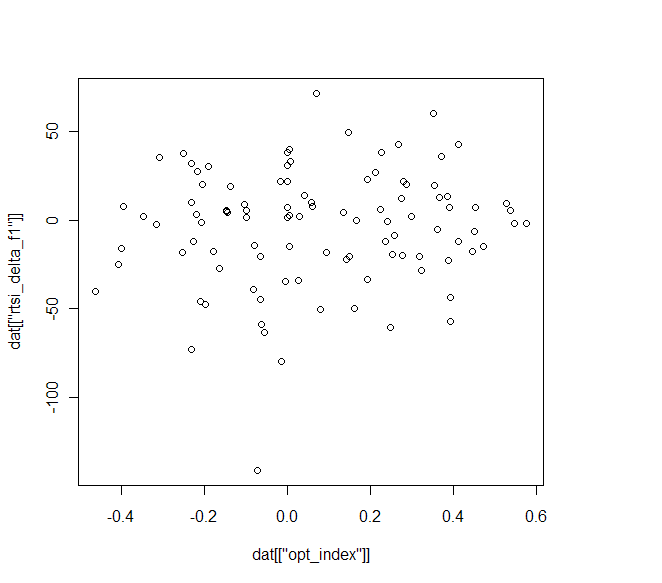
корреляция — 9%, что меньше статистической значимости, и меньше серийности RTSI — 20%(корреляция приращений текущего и следующего дня за период).
данные, картинки, код на R
теги блога vlad1024
- algotrading
- AMD
- books
- brexit
- future
- hft
- machine learning
- markets
- mercedes
- perfect world
- python
- research
- smart lab
- statistic
- stocksharp
- акции
- амд
- беспилотники
- бизнес
- биржа
- биткойн
- ВВП
- веселье
- викторина
- вопрос
- геополитика
- Глазьев
- госдума
- данные
- долгосрочные инвестиции
- доллар
- доллар рубль
- закон Яровой
- запад
- ИИ
- инвестиции
- инвестиция
- индекс оптимизма
- интернет
- инфляция
- капитализм
- коинтеграция
- коррекция
- кризис
- Кудрин
- кукловод
- ликбез
- ЛЧИ 2011
- ЛЧИ 2011
- макроэкономика
- маразм крепчал
- модель тренда
- недвижка
- нефть
- новая экономика
- опрос
- оффтоп
- патриотизм
- политика
- популяция
- прохоров
- пузыри
- регулирование
- роскомнадзор
- рубль
- рынок
- системы
- спекулянты
- спекуляции
- статистика
- ТА
- такси
- теория вероятности
- теория Доу
- технический анализ
- торговля
- торговые сигналы
- трамп
- трейдинг
- философия
- форекс
- фундамент
- Хованская
- Хронология
- ЦБ
- электромобиль
- эффективность
- эффективный рынок
- юмор
- я у мамы аналлитик
- яндекс
- яровая
Проще говоря доклад не о чем. Причина нет сути и конкретики.
Индекс оптимизма вообще вещь тоже не о чем для рядового спекулянта, коих здесь 99%.
Спасибо исследователям за работу, в очередной раз можно констатировать что рынок это совсем математика и по формуле 2+2=4 он ходить не будет.
Корелировать можно все что угодно и с чем угодно, но вы никогда не найдете даже приблизительную точность.
более прикладного характера исследование, я тоже наметил, посмотрим что получится…
Предположим что поведение толпы мы предсказали, даст ли нам это финансовую пользу или вообще что даст??? Очень сложно сказать.
Тогда жму руку за исследования)
я хотел бы сделать что-то вроде такого теста для другого консенсуса.
прошу совета.
общий алгоритм, думаю, такой:
вычислить приращения консенсуса;
вычислить приращения цены;
сделать корреляционный тест приращений цены за сегодня и приращений индекса за вчера.
все верно? или я упустил что-н? наприм., перевод в логарифмы и пр.