















Информация


Блог им. 3Qu
Моделирование Торговых Систем на Python. 2.
- 12 мая 2020, 10:29
- |

Тем, кто не читал предыдущий топик этой темы, рекомендую для начала ознакомиться с ним [1].
В комментариях к предыдущему топику меня критиковали за неоптимальность кода Python. Однако, текст читают люди с совершенно разной подготовкой — от почти не знающих Python или знающих другие языки программирования, до продвинутых пользователей. Последние легко могут обнаружить неоптимальность кода и заменить его своим. Тем не менее, код должен быть доступен и новичкам, возможно не обладающим знанием пакетов и продвинутых методов. Поэтому, в коде я буду, по возможности, использовать только базовые конструкции Python, не требующие глубоких знаний, и которые могут легко читаться людьми, программирующими на других языках. Вместе с тем, по мере изложения, без фанатизма, буду вводить и новые элементы Python.
Если вы хотите как-то улучшить или оптимизировать код, приводите его в комментариях — это только расширит и улучшит изложенный материал.
Ну, а сейчас мы займемся разработкой и тестированием индикаторов. Для начала нам нужна простейшая стратегия с использованием МА — его и построим. Самой лучшей по характеристикам МА является ЕМА. Формула ЕМА:
Y(i) = a0*X(i) + b1*Y(i-1), где a0 + b1 = 1.
Однако коэффициенты ЕМА мы будем считать по другому:
a0 = 1/(1+T/(2*pi) и b1 = T/(2*pi)/(1+T/(2*pi)), где pi = 3.14...,
что превращает ЕМА в полноценный Фильтр Нижних Частот (ФНЧ) 1-го порядка, в котором Т соответстует частоте отсечки фильтра fо = 1/T. В отличие от ЕМА, здесь параметр Т приобретает явный физический смысл, сам фильтр имеет прогнозируемые свойства, и с таким фильтром легко работать. Ну, коли он теперь фильтр, и назовем индикатор по другому cF1Bat().
Для проектирования фильтра в Python мы будем использовать классы (class). Для тех, кто не знаком с Объектно Ориентированным Программированием (ООП), class — это изолированный кусок кода, содержащий (инкапсулирующий) в себе данные и функции (методы). Объявляя или инициализируя class, мы создаем объект. Собственно, объявляя массив, структуру, строку символов или даже переменную, мы тоже создаем объекты под которые выделяется память. Все примерно тоже самое, ничего необычного.)
Ну, и сам код индикаторов:
# -*- coding: utf-8 -*-
"""
Created on Mon May 12 10:07:14 2020
@author: 3Qu
"""
import math
# Фильтр LPF 1-го порядка
class cF1Bat():
def __init__(self, per, x):
self.T = per
# self.out = []
self.Filter(x)
def Filter(self, x):
a0 = 1/(1+self.T/(2*math.pi))
b1 = self.T/(2*math.pi)/(1+self.T/(2*math.pi))
self.out = []
for i in range(0, len(x)):
if i == 0:
self.out.append(x[i])
else:
self.out.append(a0*x[i]+b1*self.out[i-1])
# 1-я производная
def d1out(self, i):
if i == 0:
return 0
return self.out[i]-self.out[i-1]
# 2-я производная
def d2out(self, i):
if i == 0:
return 0
elif i == 1:
return self.out[i]-self.out[i-1]
return self.out[i]-2*self.out[i-1]+self.out[i-2]
# Фильтр среднее за период (подходит для калибровки) T - целое
class cFMean():
def __init__(self, per, x):
self.T = per
# self.out = []
self.Filter(x)
def Filter(self, x):
self.out = []
for i in range(0, len(x)):
if i == 0:
self.out.append(x[i])
elif i > 0 and i < self.T:
self.out.append(self.out[i-1]+x[i]/self.T-x[0]/self.T)
else:
self.out.append(self.out[i-1]+x[i]/self.T-x[i-self.T]/self.T)Кроме F1Bat(), там еще дополнительно введено простое скользящее среднее cFMean() — иногда бывает нужно.
Теперь скопируем текст в в файл Filters.py. В папке SmartLab (см. пред-й топик [1]) создадим папку SLPack, и поместим в нее наш файл Filters.py. Индикаторы готовы к использованию.
Теперь остается проверить работоспособность кода и калибровки индикаторов. Для этого напишем небольшой код и сохраним его в файле Calibr.py в папку SmartLab.
# -*- coding: utf-8 -*-
"""
Created on Mon May 12 10:09:55 2020
@author: 3Qu
"""
import matplotlib.pyplot as plt
import SLPack.Filters as flt # загрузка нашего пакета с фильтрами
# создаем тестовую последовательность 1(t) - единичный скачок
x = [1 for i in range(0, 50)]
x[0] = 0
# создаем и инициализируем индикаторы
FM40 = flt.cFMean(40, x)
F40 = flt.cF1Bat(40, x)
# отображаем индикаторы на графике
plt.plot(FM40.out, label = 'FM40') # добавили ярлык на график
plt.plot(F40.out, label = 'F40')
plt.title('Реакция на 1(t)') # заголовок
plt.legend() # отображаем ярлыки и легенду (если есть)
plt.grid()
plt.show()Запускаем файл Calibr.py на исполнение и получаем картинку:

Как видим, все работает и идеально откалибровано, что и следовало ожидать от правильно построенного фильтра.
Думаю, теперь вы можете самостоятельно построить наши индикаторы на графике случайного блуждания [1], вывести на график заголовок, ярлыки и поэкспериментировать со всем этим.
Удачи!
Ссылки.
1. Моделирование Торговых Систем на Python. 1.
теги блога 3Qu
- Binance
- C#
- C++
- DDE
- DLL
- EMA
- Excel
- Exponential Moving Average
- Lua
- machine learning
- metatrader5
- ML
- MOEX
- Moving Average
- Python
- QLua
- Quik
- Quik Lua
- Si
- Smart-lab
- SQLite
- автоматическая торговая система
- акции
- алготрейдинг
- базы данных
- Баффет
- биржа
- Боллинджер
- Брокер
- брокеры
- вероятность
- выбор
- Газпром
- дельта
- доллар
- Доллар рубль
- доска опционов
- идеология
- инвестиции
- индикатор
- индикаторы
- интрадей
- календарный спред
- календарный спрэд
- Кризис
- криптовалюта
- МА
- Машинное обучение
- моделирование
- модель
- нейросети
- нейросеть
- нефть
- опрос
- опционные стратегии
- опционы
- оффтоп
- плечо
- прогнозирование
- программирование
- психология
- реклама
- роботы
- рынок
- сеточник
- скальпинг
- скользящие средние
- случайное блуждание
- спекуляции
- спекуляция
- статистика
- стационарность
- стоп
- стопы
- Стратегии
- стратегия
- стрэддл
- стрэнгл
- Тейк
- терминал
- тест
- тестер стратегий
- тестирование
- технический анализ
- торговая система
- торговая стратегия
- торговые роботы
- торговые системы
- торговые стратегии
- торговый софт
- трейдинг
- ТС
- фильтр
- Фильтры
- Форекс
- фундаментальный анализ
- фьючерс
- фьючерс ртс
- фьючерсы
- эффективный рынок
Правильно критиковали. На питоне легко писать, как хороший код так и плохой.
1. Ну PEP же есть. Любой pycharm вам подстветит, что функции всегда в snake_case должны быть. Uppercase только нейминг классов. А у вас все наоборот. PEP не случайно придуман, при импорте всегда понятно что вы импортируете.
2. Объявление атрибута за пределами __init__ плохая практика. В вашем кейсе оно ничего конечно не сломает, но вы же пытаетесь научить людей. А такому учить не надо.
3. Ну логика в __init__ тоже как бы не очень. Немного нелогично делать основные вычисления при инициализации объекта, особенно, если там еще и exception свалится может.
4. Зачем else если после if вы делаете return? Лапша if-else всегда плохо читается.
5. Зачем вам там вообще классы? вам достаточно 2х функций, которые будут возвращать tuple, ну или namedtuple, если очень хочется. Ну это дело вкуса больше, но классы имеют overhead.
6. # -*- coding: utf-8 -*- да не нужно уже это. вы что на 2,7 пишете?
7. Да и про numpy правильно писали. Не делают нормальные люди числовые операции на python листах. Это некрасиво (циклы) и медленно.
day0markets, вы нативно разраб или работая с прикладными задачами так поднатаскались?))
2. Это типа когда первый раз поле класса первые раз упоминается (присвоение) вне __init__()? — Интуитивно пришел к тому, что это не айс. Т.е. даже если при инициализации значение не известно надо типа заглушку поставить — а-ля None? — Так выглядит правильная практика?
4. Какая альтернатива есть else-if лапше? Даже свичей нет в питоне, как я понимаю.
Replikant_mih, разраб + прикладных много + собеседований провел немало)
2. Дефолт надо. None не всегда подойдет, возможно, надо пустой лист или словарик, ну или что там ожидается. Ну я сам по возможности использую typing, особенно на больших и сложных классах.
4. Уменьшить вложенность по возможности. Switch та же хрень в целом. Я два подхода использую:
-быстрая проверка на значение которое можно сразу вернуть или пробросить exception и потом уже тело функции без else
-если кейсов много, то логику в if/else вынести в функции (можно лямбды иногда) и к ним словарик с колбеками. по условию находим нужный колбек и его дергаем. хорошо заходит, если после if идет большой процессинг и вариантов на проверку много
day0markets, 2. Дефолт — типа пустое значение соответствующего типа, если ожидается словарь — {}, если список — [] и т.д. — я как-то так делаю).
typing — это про аннотацию типов? — аннотация типов классная штука, недавно открыл. Единственное, придумал как замутить аналог перечислений через конструкции вида:
class A:
a = 'a'
b = 'b'
Но в аннотации конечно же var = A.a — это строка, а хочется: var: A. )
4. После «вынесем в функцию» когда начались «словарики и колбеки» перестал понимать, о чем речь)).
1. снимите коммент # в __init__() и будет вам объявление out.
2. else там действительно лишнее, надо будет убрать.
3. Питону в блогах не научишь, такая задача не ставилась.
Остальное несущественно.
ну так почти все программистишки и пишут говнокод. что тут нового?
В production, конечно, нормальные люди числодробительные операции выносят во что-нибудь. Но на этапе обучения разве они сразу сходу numpy изучают? :)
она же, только в упрощённом виде (в том виде в котором и надо записывать в код):
Не вижу объективных причин не использовать сервисы для написания формул.
v_0ver, уважаемый, Вы за год написали 5 топиков по 1 абзацу в каждом. А от благородного 3Qu требуете оформление как в рецензируемом журнале.
Написали бы пару содержательных топиков по 5-10 килобайт каждый. Вставили в них формулы красивые и графики интересные. Да хотя бы на тему "Показываю грааль (на Питоне)". Сообщество было бы Вам благодарно и аплодировало. Ругать мы все мастера. А надо своим примером, своим примером.![]()
раньше был перл, пхп, яваскрипт, рабби какой то. теперь питон бля.
всё это мода. а по сути все эти «языки» — обычный бейсик.
онли с++ вечен, пацаны.
аминь.
Мне понравилось, может быть и я слезу с дивана и начну питон изучать.
Пишите еще.
Хороший программист должен:
1. Уметь улучшить и сократить любую программу.
2. Никогда этого не делать.
П.2 я неукоснительно выполняю, а потому проверить, могу ли я выполнить п.1. не представляется возможным.) Думаю, что да, но тогда нарушу п.2.)
Выражение для эквити в данном случае имеет аналитическое представление. Не самое простое, зато значительно лучше подходящее для анализа.
С уважением
P.S. Ни в одной МА с тюнингом, ни в наборе МА Грааля нет…
Только у вас у F40 и FM40 временной лаг будет разный. Не то чтобы это неправильно, но это надо учитывать и чётко осознавать почему мы делаем именно так а не иначе.
Просто на рынке запаздывание индикатора более важная характеристика чем то какие частоты он фильтрует ) Частот-то строго говоря каких-то особенных нет )
Так я сам пользую в основном EMA разных периодов, как раз именно потому что у них есть понятный естественный фильтрующий смысл.
Где-то в своем блоге я уже описывал ФНЧ 2-го порядка, но и этой конструкции уже лет 10, и она изначально не оч правильная в смысле нормирования.
3Qu, ну это некий волюнтаризм, но ладно, предположим.
Я скорее имею в виду, что на рынке довольно важны такие вещи как локальные минимумы и максимумы цены, и соответственно временная разница между максимумами цены и фильтрующего индикатора, безотносительно каких-то конкретных частот которых на самом деле нет.
У EMA по вашей формуле при параметре 40 лаг будет где-то 6.5, а у SMA ровно 20, неслабая такая разница, а глядя на параметр можно подумать что это примерно одно и то же, если в формулу не посмотреть.
А так конечно пожалуйста, хозяин барин, только умножений в ваших формулах слишком много, обычно это оптимизируют перестановкой операций и скобок.
Ну, у меня уже не ЕМА.)
Локальные максимумы и минимумы с помощью фильтров как раз оч хорошо определяются. Просто вы не умеете их готовить. © )) Но я предпочту на эту тему не оч распространяться.)
Может быть вы думаете что EMA это что-то другое, но это оно и есть что у вас написано, просто деление на 2pi добавлено.
Возьмем два разных фильтра ФНЧ с одной формулой и разными коэффициентами — это уже фильтры разных типов. Один, скажем, Чебышева, а другой Бесселя. И свойства у них разные, а общая формула одна и та же.)
У ЕМА своя метода расчета коэффициентов от Т.
Впрочем, неважно, дискуссия чисто терминологическая. Я подобные фильтры уже давно не применяю.
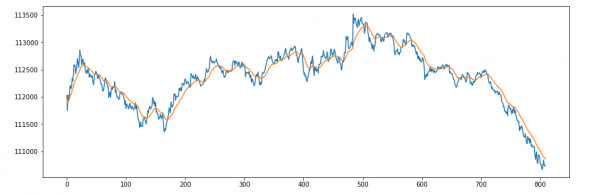
Пример 1 минутного графика RIM0 за 12 мая 2020 с ЕМА-21
import pandas as pd
import matplotlib.pyplot as plt
#Читаем в датафрейм candles минутки RIM0 за 12 мая 2020. Загружены с Финама, лежат в «загрузках» в текстовом формате
candles=pd.read_csv('C:\\Users\\User\\Downloads\\SPFB.RTS-6.20_200512_200512.txt', header=0, sep=';')
#Создаем столбец 'ema21' применяя ЕМА к цене закрытия (столбец '<CLOSE>')
candles['ema21'] = pd.Series.ewm(candles['<CLOSE>'], span=21).mean() #собственно расчет ЕМА-21
#Отрисовываем цену закрытия и ЕМА-21
plt.figure(figsize=(15,5))
plt.plot(candles['<CLOSE>'])
plt.plot(candles['ema21'])
plt.show()
Результат:
Используем библиотеку pandas.
Тимофей, чего у тебя код в комменты нельзя вставить, только в топик?
candles.plot(y=['<CLOSE>', 'ema21'], figsize=(15,5))
def Filter(self, x): a0 = 1/(1+self.T/(2*math.pi)) b1 = self.T/(2*math.pi)/(1+self.T/(2*math.pi)) self.out = [x[0]] for i in range(1, len(x)): self.out.append(a0*x[i]+b1*self.out[i-1])Перейду к сути, есть индикатор на Lua, но как понял в Квике бэктест не возможен.Скажите пожалуйста, на Питоне вы делаете бэктест? есть такая возможность.