

SMART-LAB
Новый дизайн
Мы делаем деньги на бирже














Информация


 Новости тг-канал
Новости тг-каналИзбранное трейдера Лехус
Алготрейдинг: с чего начать...
- 25 сентября 2014, 01:30
- |

Всем бобра!
Мною было принято решение поставить эксперимент. Суть проста: меня всегда вдохновляла возможность в современном мире жонглируя цифрами получать по голове фидбек быстро и материально. В этом плане рынок со всеми его достоинствами и недостатками идеальное место. У кого-то получается, кто-то спекулирует этой возможностью, кто-то бьется лбом об стенку. Поэтому было принято потратить 4-5-6 месяцев и получить для себя ответ на вопрос «могу ли я зарабатывать на фондовом рынке». Конечно есть много способов (особенно в РФ) заработать быстрее и в перспективе больше, однако большинство из них лежат в плоскостях не очень мне интересных или требуют ведения нечестной игры. Также не принимаются к обсуждению сентенции вроде «рынок не торт, рашка гуано»...
Поскольку лучший вариант разобраться в вопросе (тем более в таком мутном) — набить шишки самому, я решил последовательно перебирать, тестировать стратегии, и для систематизации работы решил вести дневник. Почему бы не добавить немного социализации и выкладывать часть результатов на сайт? Возможно тот кто уже давно прошел начальный путь и находится дальше или просто делал что-то похожее поможет советом или укажет на ошибки.
( Читать дальше )
Мною было принято решение поставить эксперимент. Суть проста: меня всегда вдохновляла возможность в современном мире жонглируя цифрами получать по голове фидбек быстро и материально. В этом плане рынок со всеми его достоинствами и недостатками идеальное место. У кого-то получается, кто-то спекулирует этой возможностью, кто-то бьется лбом об стенку. Поэтому было принято потратить 4-5-6 месяцев и получить для себя ответ на вопрос «могу ли я зарабатывать на фондовом рынке». Конечно есть много способов (особенно в РФ) заработать быстрее и в перспективе больше, однако большинство из них лежат в плоскостях не очень мне интересных или требуют ведения нечестной игры. Также не принимаются к обсуждению сентенции вроде «рынок не торт, рашка гуано»...
Поскольку лучший вариант разобраться в вопросе (тем более в таком мутном) — набить шишки самому, я решил последовательно перебирать, тестировать стратегии, и для систематизации работы решил вести дневник. Почему бы не добавить немного социализации и выкладывать часть результатов на сайт? Возможно тот кто уже давно прошел начальный путь и находится дальше или просто делал что-то похожее поможет советом или укажет на ошибки.
( Читать дальше )
- комментировать
- ★15
- Комментарии ( 31 )
Торговый робот на LUA для QUIK.
- 27 августа 2014, 10:34
- |
Написал скрипт на языке Lua для торгового терминала QUIK.
И назвал его Торговый робот «Lbot».
Предназначил для автоматизации выполнения торговых операций на фондовом рынке.
Обязал выполнять операции купли-продажи заданной ценной бумаги на фондовом рынке путем выставления лимитированных биржевых заявок.
Научил понимать слова из правил торговой стратегии, задаваемой из файла настроек в формате ini:

Добавил возможность управления позициями путем нажатий соответствующих кнопок.
Подробнее на сайте: http://www.xsharp.ru/
И назвал его Торговый робот «Lbot».
Предназначил для автоматизации выполнения торговых операций на фондовом рынке.
Обязал выполнять операции купли-продажи заданной ценной бумаги на фондовом рынке путем выставления лимитированных биржевых заявок.
Научил понимать слова из правил торговой стратегии, задаваемой из файла настроек в формате ini:
- OpenLong — вход в длинную позицию;
- CloseLong — закрытие длинной позиции;
- OpenShort — открытие короткой позиции;
- CloseShort — закрытие короткой позиции;
- StopLoss — закрытие позиции по стоп-лоссу;
- TakeProfit — закрытие позиции по тэйк-профиту.

Добавил возможность управления позициями путем нажатий соответствующих кнопок.
Подробнее на сайте: http://www.xsharp.ru/
FAQ по системе Романа Андреева
- 06 августа 2014, 11:00
- |
Если кто-то не знает Романа, вот ссылка на профиль: smart-lab.ru/profile/RomanAndreev/
Собирал информацию для себя, перечитывая блог с начала, но в связи с тем, что в ветке появляется много новичков и задаются почти однотипные вопросы, решил выложить для всех.
Для новеньких в блоге
В таблице, все что относится к системной среднесрочной трендовой торговле. Прочитайте первый пост Романа smart-lab.ru/blog/135947.php и информацию о системе ниже — думаю, вопросов не должно остаться.
Стоп в таблице — это просто стоп-заявка для переворота позиции. Если по итогам стопа образовалась прибыль — значит это был тейк-профит, если убыток — стоп-лосс. Для бумаг, по которым произошел переворот, прибыль/убыток по предыдущей позиции указывается в столбце P/L%
В комментариях Роман также озвучивает уровни для внутридневной торговли — это расчетные уровни стопов, за которыми охотятся крупные игроки, создавая движения на рынке. Если решите торговать эти уровни -
( Читать дальше )
Собирал информацию для себя, перечитывая блог с начала, но в связи с тем, что в ветке появляется много новичков и задаются почти однотипные вопросы, решил выложить для всех.
Для новеньких в блоге
В таблице, все что относится к системной среднесрочной трендовой торговле. Прочитайте первый пост Романа smart-lab.ru/blog/135947.php и информацию о системе ниже — думаю, вопросов не должно остаться.
Стоп в таблице — это просто стоп-заявка для переворота позиции. Если по итогам стопа образовалась прибыль — значит это был тейк-профит, если убыток — стоп-лосс. Для бумаг, по которым произошел переворот, прибыль/убыток по предыдущей позиции указывается в столбце P/L%
В комментариях Роман также озвучивает уровни для внутридневной торговли — это расчетные уровни стопов, за которыми охотятся крупные игроки, создавая движения на рынке. Если решите торговать эти уровни -
( Читать дальше )
За Семь Часов до Атаки, или Помогите Найти Кукла!
- 30 октября 2013, 15:07
- |
- Московский Лоссбой

Я на рынке начинающий Разумный Инвестор и далеко не самый умный и знающий, поэтому тщательно прислушиваюсь к мнению всех специалистов, аналитиков, экспертов и прочих биржевых обозревателей, которым доступные многие скрытые от меня тайны рынка. Ежедневно «от корки до корки» читаю новостную ленту Интерфакса, изучаю все аналитические обзоры на Смарт-Лабе, подробно вникаю в аргументированные прогнозы авторитетных участников (только покупка, только продажа, футпринты показали явную дистрибуцию в области аккумуляции чуть выше надёжной многолетней поддержки по 100-месячным скользящим средним проколом хаёв и лоёв, пора сходить вбок, десятикратная дивергенция позволяет сделать вывод о наметившемся выходе из зоны перепродаж ). Я подкован :) Из всех телеканалов оставил только РБК, но зато в каждой комнате. Даже в сортире доносится приятный баритон Карабянца. Каждый Разумный Инвестор, как я, должен круглосуточно находиться рядом со знающими людьми, которые ведут просветительскую деятельность и, вместо того, чтобы тихо и спокойно зарабатывать самим, абсолютно бесплатно готовы поделиться со мной своими знаниями. Абсолютно бесплатно! Как же это здорово и приятно! Внимать им и почитать за счастье успеть последовать их советам – кого купить, кого продать. Они же знают лучше, чем я, иначе не я их, а они бы смотрели меня по ящику, раскрыв рот.
( Читать дальше )
( Читать дальше )
Два года на рынке. Трейдинг – не мое
- 31 мая 2013, 10:07
- |
Сегодня ровно два года, как я начал торговать. Если не считать первые два месяца, когда я просто пытался интуитивно угадать направление цены, слив при этом почти весь депозит, то все это время мой трейдинг заключался в работах над созданием механической торговой системы. Тесты, проверки, анализ, роботы, тесты, проверки, анализ, роботы… И если год назад, когда я писал свой отчет «Год на рынке», я был воодушевлен и дальше вести поиски в этом направлении, то сейчас я потерял к этой работе интерес.
( Читать дальше )
( Читать дальше )
Про поиск паттернов
- 27 апреля 2011, 03:16
- |
В последнее время довольно много времени провожу в поисках ценовых паттернов. Интересно, что паттернов, которые явно не случайны довольно много. Неслучайностью предлагаю считать все, что с вероятностью более 50% ведет себя предсказуемо. Например, растет или падает после появления фигуры. Дык вот, оказалось, что главная проблема не в том как найти паттерн, это довольно легко автоматизировать, но проблема в том, что даже если паттерн срабатывает, этого не достаточно для того, чтобы сделать из него что-то путное. Дело в том, что многие паттерны даже при всей своей неслучайности не способны обеспечивать устойчивое отношение средней прибыли к убыткам больше 1. В этом основная проблема. Я объясняю это распределением размера прибыли по «сделкам». Если скажем взять и посчитать какова была максимальная прибыль в растущих днях, то получится вот такая картинка:
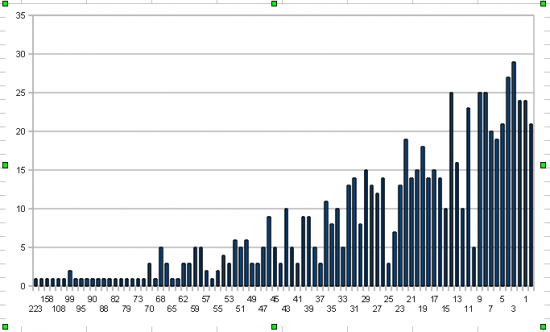
Цифры внизу, это отношения: (close — open) / 100. То есть «купил и держи». Купил на самом открытии и продержал до самого закрытия. А слева, это то, сколько раз это отношение встречалось в истории с середины 2005 года. Поэтому не все паттерны одинаково полезны. Нужно найти не просто неслучайный вход, но еще и такой вход, который может обеспечить прибыль хотя 1.5 к 1. Да, первичную проверку я делаю так. Заходим по сигналу от паттерна. Выходим на следующий день на открытии.
Интересно было бы также узнать какие методики вы применяете при поиске паттернов?
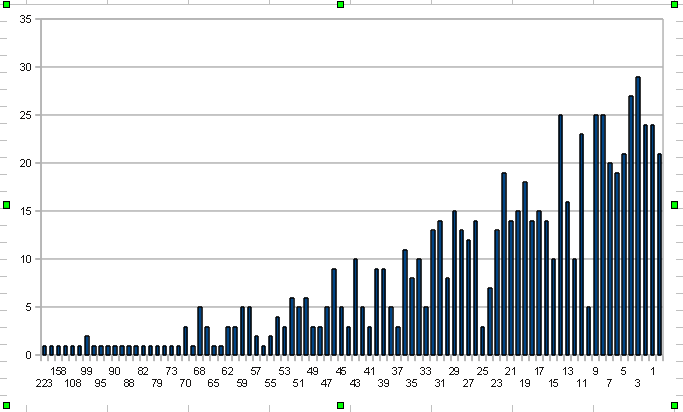
Цифры внизу, это отношения: (close — open) / 100. То есть «купил и держи». Купил на самом открытии и продержал до самого закрытия. А слева, это то, сколько раз это отношение встречалось в истории с середины 2005 года. Поэтому не все паттерны одинаково полезны. Нужно найти не просто неслучайный вход, но еще и такой вход, который может обеспечить прибыль хотя 1.5 к 1. Да, первичную проверку я делаю так. Заходим по сигналу от паттерна. Выходим на следующий день на открытии.
Интересно было бы также узнать какие методики вы применяете при поиске паттернов?
- bitcoin
- brent
- eurusd
- forex
- gbpusd
- gold
- imoex
- ipo
- nasdaq
- nyse
- rts
- s&p500
- si
- usdrub
- wti
- акции
- алготрейдинг
- алроса
- аналитика
- аэрофлот
- банки
- биржа
- биткоин
- брокеры
- валюта
- вдо
- волновой анализ
- волны эллиотта
- вопрос
- втб
- газ
- газпром
- гмк норникель
- дивиденды
- доллар
- доллар рубль
- евро
- золото
- инвестиции
- индекс мб
- инфляция
- китай
- кризис
- криптовалюта
- лукойл
- магнит
- ммвб
- мобильный пост
- мосбиржа
- московская биржа
- мтс
- натуральный газ
- нефть
- новатэк
- новости
- обзор рынка
- облигации
- опрос
- опционы
- отчеты мсфо
- офз
- оффтоп
- прогноз
- прогноз по акциям
- путин
- раскрытие информации
- ри
- роснефть
- россия
- ртс
- рубль
- рынки
- рынок
- санкции
- сбер
- сбербанк
- северсталь
- сигналы
- смартлаб
- сущфакты
- сша
- технический анализ
- торговля
- торговые роботы
- торговые сигналы
- трамп
- трейдинг
- украина
- фондовый рынок
- форекс
- фрс
- фьючерс
- фьючерс mix
- фьючерс ртс
- фьючерсы
- цб
- цб рф
- экономика
- юмор
- яндекс