

SMART-LAB
Новый дизайн
Мы делаем деньги на бирже














Информация


 Новости тг-канал
Новости тг-каналКомментарии пользователя Alex Craft
Никто, это задача требующая полноценной занятости, океан данных и т.п. фонд Дж Симонса, и т.п. Показать никто не покажет, потому что кто умеет скрывает, а другим показать нечего.
- 25 января 2025, 12:30

Еще наблюдение — после нормализации, на графике распределения вероятностей исчезли «особенности» (разные горбы и перекосы) для отдельных акций, и он стал напоминать колокол (с хвостами).
- 24 января 2025, 14:02
amberfoxman, оптимальный портфель по марковицу? Насколтко знаю, он игнорирует ключевой компонент — системный риск, нестационарность корреляций при падение рынка, когда у всех акций корреляция становится 1.
- 19 января 2025, 09:12
Опционный деск — это текущие цены опционов? Непонятно — как это поможет? Ведь цель — определить цены опционов, и сравнив их с текущими найти расхождения.
- 19 января 2025, 08:59
Это нечто, сюрприз — после нормализации по медиане и сигме, у «спокойной» MCD разброс получается больше чем у «волатильной» AMD.


- 19 января 2025, 07:15
Видно как они стабилизируются, если увеличить интервал до 20 лет, и превращаются в гладкие и плавные кривые.




- 19 января 2025, 05:43
Интересно было посмотреть в этом эксперименте Обобщенное Гиперболическое. Но, оно не впечатлило, оно работает не лучше чем Ассиметричный Гауссовский Микс со Средними = 0 из прошлых постов.
Возможно Гиперболическое может быть интересно если нужна аналитическая форма распределения, но мне она не нужна, я использую численные методы и симуляции, и с Гауссовским Миксом работать проще, интуитивно понятней, и аппроксимирует он не хуже.
Возможно Гиперболическое может быть интересно если нужна аналитическая форма распределения, но мне она не нужна, я использую численные методы и симуляции, и с Гауссовским Миксом работать проще, интуитивно понятней, и аппроксимирует он не хуже.
- 13 января 2025, 15:11
Но чисто для аппроксимации, когда маштабировать не нужно, получается хорошее приближение. Нопример посмотреть симуляции, с известным теоретическим распределением, которое в то же время достаточно близко к реальному.
- 13 января 2025, 14:35
Подумал, все таки наверно лучше принудительно поставить условие для «среднего» в гауссовых компонентах равным нулю, и отдельно считать левую и правую часть чтоб учесть ассиметрию. Тогда маштабировать можно меняя сигму с сохранением пропорций.
С произвольно гуляющими средними слишком непонятно получается, теряется понятие сигмы как меры волатильности
С произвольно гуляющими средними слишком непонятно получается, теряется понятие сигмы как меры волатильности
- 13 января 2025, 14:28
Михаил, посмотрел в содержании, есть главы посвещенные VAR используя вероятности и корреляции, с учетом редких событий, но все таки полагаясь на вероятности.
Насколько я понимаю, Мандельброт/Талеб — предлагают другой подход, они считают вероятностный подход к защите от риска принципиально неверным. И предлагают вместо вероятностей использовать механические, детерминированные защиты. Как например страховка пут опционами, либо ассимметричный (barbel) портфель, где основная часть в супербезопасных (и практически безприбыльных) активах.
Насколько я понимаю, Мандельброт/Талеб — предлагают другой подход, они считают вероятностный подход к защите от риска принципиально неверным. И предлагают вместо вероятностей использовать механические, детерминированные защиты. Как например страховка пут опционами, либо ассимметричный (barbel) портфель, где основная часть в супербезопасных (и практически безприбыльных) активах.
- 13 января 2025, 05:54
RoboScalp, это нужно для получения будущего распределения вероятностей цен акций — на следущий месяц, или полгода, или год.
- 12 января 2025, 14:07
Для макдональдса, разница между линией МиксовойМодели и ПростогоНормального особенно заметна:
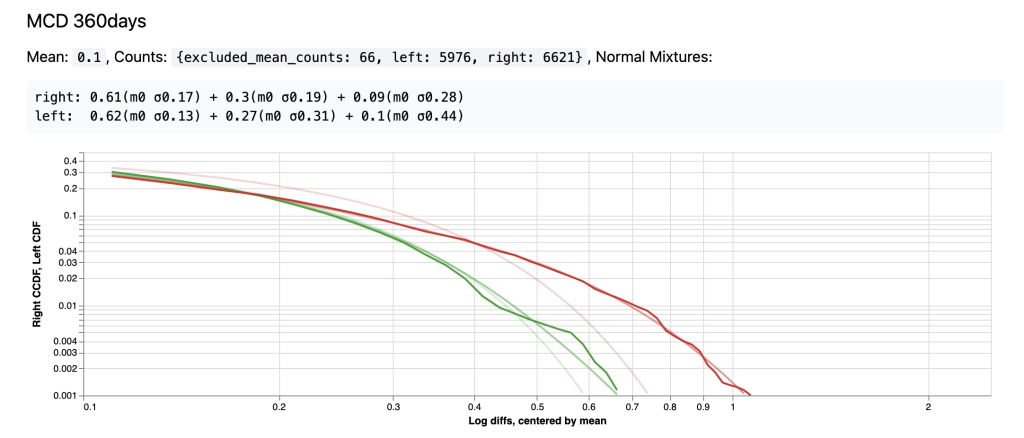
- 12 января 2025, 13:49
А почему предсказание дивидендов, а не прибыли (чистой или грязной)?
С дивидендами проблема — компании могут по разному их выплачивать, кто то напрямую дивиденды платит, кто то может скупать свои акции, кто то инвестирует в рост компании. Нет единообразия, не получается сравнивать напрямую компании.
Анализ прибыли, как грязной так и чистой — он более единообразен для всех компаний, его может быть легче предсказать.
А как конкретно прибыль компании выльется в прибыль держателя акций — в виде явных дивидендов, либо роста акций, вобщем то не важно.
С дивидендами проблема — компании могут по разному их выплачивать, кто то напрямую дивиденды платит, кто то может скупать свои акции, кто то инвестирует в рост компании. Нет единообразия, не получается сравнивать напрямую компании.
Анализ прибыли, как грязной так и чистой — он более единообразен для всех компаний, его может быть легче предсказать.
А как конкретно прибыль компании выльется в прибыль держателя акций — в виде явных дивидендов, либо роста акций, вобщем то не важно.
- 12 января 2025, 05:49
Сергей Олейник, в данном случае у нас простой случай — определить параметры искуственного распределения которое мы заведомо знаем.
- 11 января 2025, 14:54
E L, в том то и дело, весь смысл этих графиков и поисков — это измерение текущей волатильности :). Текущая волатильность невидима, она не поддается прямому измерению, мы видим, скажем в данных за последней месяц — лишь часть ее.
- 10 января 2025, 12:32
E L, именно это я и делаю :). Если бы меня не интересовали изменения волатильности, я бы просто использовал эмпирическое распределение за несколько десятков лет, с фиксированной волатильностью, вообще сходу делается.
Но мне нужно найти а) общую форму распределения («истинное» распределение) основываясь на десятках лет истории и «гадании/индукции/интуиции разглядывания графиков» и б) как откалибровать ее волатильность на текущей волатильности за последний год или месяцы.
Проблема с прямым измерением волатильности на текущий момент (скажем за последний месяц, или последнюю неделю) — она не поддается измерению напрямую, она не репрезентативна. Слишком мало данных.
Ее можно измерить только опосредственно. Используя «нерепрезентативный» замер текущей волатильности за скажем последний месяц, и затем калибруя по нему «истинное» распределение, чтобы получить настоящее, репрезентативное значение текущей волатильности.
Но мне нужно найти а) общую форму распределения («истинное» распределение) основываясь на десятках лет истории и «гадании/индукции/интуиции разглядывания графиков» и б) как откалибровать ее волатильность на текущей волатильности за последний год или месяцы.
Проблема с прямым измерением волатильности на текущий момент (скажем за последний месяц, или последнюю неделю) — она не поддается измерению напрямую, она не репрезентативна. Слишком мало данных.
Ее можно измерить только опосредственно. Используя «нерепрезентативный» замер текущей волатильности за скажем последний месяц, и затем калибруя по нему «истинное» распределение, чтобы получить настоящее, репрезентативное значение текущей волатильности.
- 10 января 2025, 12:29
Михаил, и избежать нахождения некой сложной кривой которая хорошо подойдет для правдоподобия за счет оверфиттинга .
- 10 января 2025, 08:37
Михаил, я хочу видеть каждый шаг, визуально, чтоб понимать что происходит и исключить ошибки.
- 10 января 2025, 08:23
Владимиров Владимир, это же обоюдный случай. Слишком дешево — можно купить, слишком дорого — можно продать :)
- 08 января 2025, 11:25

Выберите надежного брокера, чтобы начать зарабатывать на бирже:
- bitcoin
- brent
- eurusd
- forex
- gbpusd
- gold
- imoex
- ipo
- nasdaq
- nyse
- rts
- s&p500
- si
- usdrub
- wti
- акции
- алготрейдинг
- алроса
- аналитика
- аэрофлот
- банки
- биржа
- биткоин
- брокеры
- валюта
- вдо
- волновой анализ
- волны эллиотта
- вопрос
- втб
- газ
- газпром
- гмк норникель
- дивиденды
- доллар
- доллар рубль
- евро
- золото
- инвестиции
- индекс мб
- инфляция
- китай
- кризис
- криптовалюта
- лукойл
- магнит
- ммвб
- мобильный пост
- мосбиржа
- московская биржа
- мтс
- натуральный газ
- нефть
- новатэк
- новости
- обзор рынка
- облигации
- опрос
- опционы
- отчеты мсфо
- офз
- оффтоп
- прогноз
- прогноз по акциям
- путин
- раскрытие информации
- ри
- роснефть
- россия
- ртс
- рубль
- рынки
- рынок
- санкции
- сбер
- сбербанк
- северсталь
- сигналы
- смартлаб
- сущфакты
- сша
- технический анализ
- торговля
- торговые роботы
- торговые сигналы
- трамп
- трейдинг
- украина
- фондовый рынок
- форекс
- фрс
- фьючерс
- фьючерс mix
- фьючерс ртс
- фьючерсы
- цб
- цб рф
- экономика
- юмор
- яндекс